← Back to The Signal
Architecture
December 8, 2025
The Modern AI Stack: 13 Layers from LLM to Production
How to move from fragile pilots to production-grade AI
Nick Amabile
Founder & CEO
Updated: February 3, 2026
How to move from fragile pilots to production-grade AI
Every enterprise AI deck has the slide. A neat little diagram: UI → LLM → Tools → Profit.
It looks clean. It's also wrong.
When you move from a demo to a production system that touches real customers, real money, and real risk, that three-box diagram explodes into a dense, distributed system: dozens of services, multiple data stores, orchestration engines, safety layers, governance processes, and teams who all have to live with it in production.
Most failed AI pilots don't fail because of the model. They fail because the architecture is hand-wavy and the organization isn't set up to own it.
At Ultrathink, we built the Modern AI Application Stack because we needed a brutally honest map of what it actually takes to run agentic, LLM-powered systems in production—inside real enterprises with legacy systems, risk teams, compliance constraints, and executives who expect measurable outcomes, not "labs."
This isn't a thought experiment. It's the blueprint behind Ultrathink Axon™, our production platform, and the way we design and run AI systems for clients.
When most people think "LLM app," they think chatbot. But the LLM application stack required for enterprise use cases goes far beyond a simple chat interface calling an API.
A production LLM app stack includes model gateways for routing and cost management, retrieval-augmented generation (RAG) systems for injecting business context, tool orchestration via protocols like MCP, durable execution for reliability, and safety layers including guardrails and human-in-the-loop workflows.
The organizations succeeding with LLMs aren't building chatbots. They're building intelligent systems that coordinate across models, tools, data stores, and human reviewers to accomplish complex business workflows—claims processing, underwriting, customer service escalation, contract review.
There's a reason so many enterprise AI pilots never reach production. It's not that the models don't work—it's that organizations drastically underestimate the infrastructure required to run AI at scale.
A demo can hide its sins. It runs on a developer's laptop. It doesn't need to handle failures gracefully. It doesn't need to audit every decision. It doesn't need to integrate with your existing systems or satisfy your compliance team.
Production AI is different. It's a distributed system that calls models, tools, and data across dozens of services—and fails like a distributed system too. Without a complete stack addressing orchestration, safety, evaluation, and governance, your pilot will remain a fragile demo.
This is the AI Execution Gap—and closing it requires understanding and investing in every layer of the modern AI application stack.
Dive deeper with reference architectures, vendor options, and implementation patterns.
The Modern AI Application Stack: A complete blueprint for production AI-powered applications
You don't start with architecture diagrams. You start with use cases and KPIs.
We use our Action Potential Index™ (API) to score and prioritize use cases based on impact, feasibility, risk tolerance, and data readiness, and our Model Efficacy Audit to match those use cases to the right models and architecture shape. These tools live inside The Synapse Cycle™, our methodology for moving from ambiguity to a production-ready roadmap in weeks, not months.
Only then do we apply the stack.
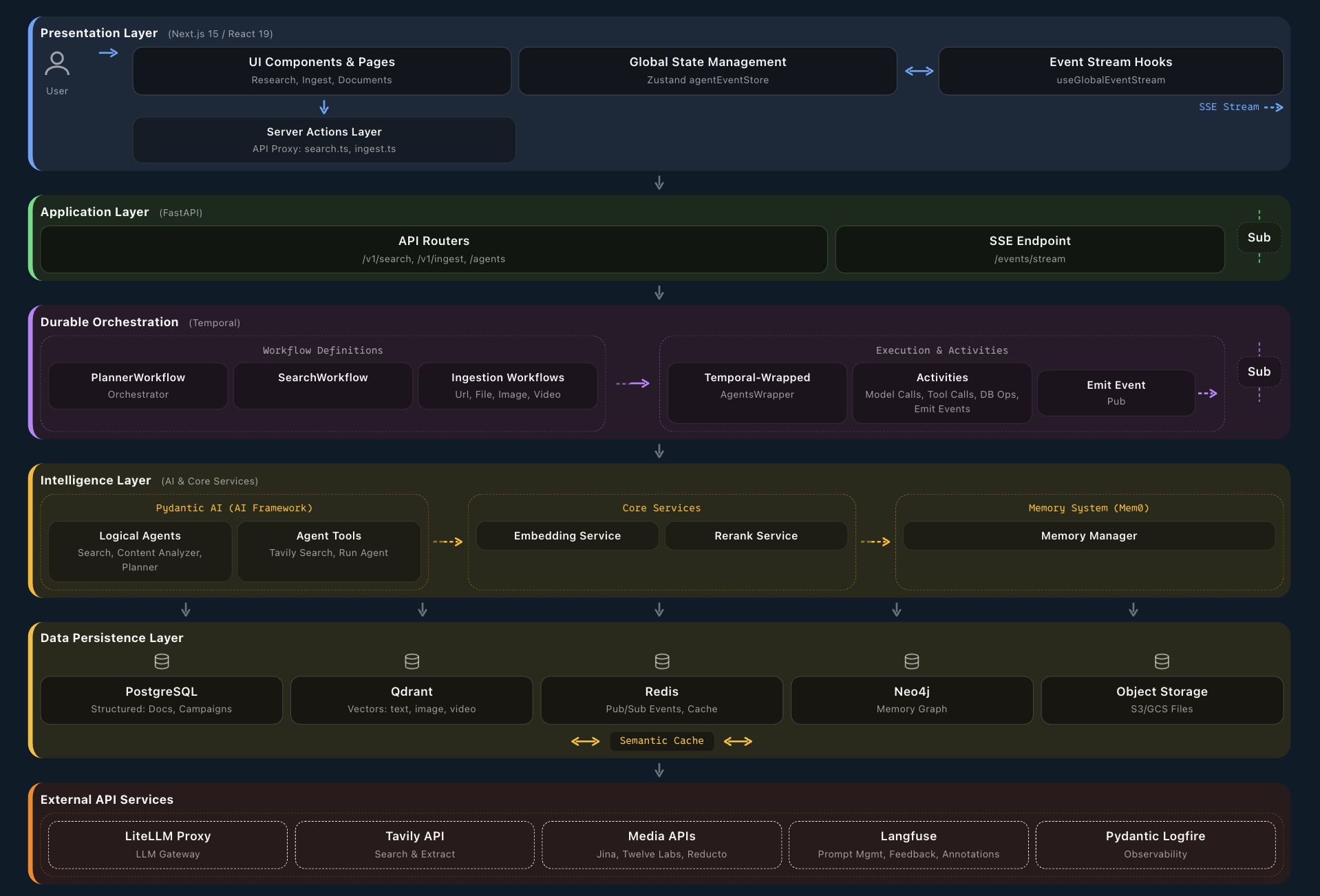
Here's the full picture we use internally and with clients:
The rest of this post is a pragmatic walkthrough of each layer—what it is, why it exists, and what breaks if you ignore it.
This is what users actually see: the front-end and application APIs.
For internal workflows, chat is often a bad interface. The best systems use tailored UIs for specific workflows—refund approvals, claims investigation, underwriting, pricing, case triage—with agents and LLMs working behind the scenes.
The key responsibilities here:
If this layer is weak, everything else can be perfect and the user experience will still feel like a toy.
AI applications don't replace your infrastructure; they stack on top of it.
Underneath Axon, we still run: Kubernetes or managed container platforms, relational databases for core application data, graph and document stores where appropriate, columnar/analytical databases (e.g., ClickHouse) to power things like Langfuse-style tracing and analytics, secret management, RBAC, identity providers, CI/CD, logging, metrics, and alerting—the usual suspects.
The twist: AI workloads add a lot more surface area:
We've baked this into Axon so clients don't have to reinvent the entire stack just to run a handful of AI applications.
This is where a lot of "you're not AI-ready because your data isn't perfect" FUD lives.
Reality: most enterprises already have serious data infrastructure—data warehouses, lakes, CDC pipelines, integration platforms. Our job is not to rebuild that. It's to augment it for AI.
For AI workloads, we focus on:
The key message: data perfection is not a prerequisite. With the right semantic modeling and ingestion patterns, we can make you AI-ready far faster than a multi-year "data first" initiative.
This is one of the most misunderstood layers—and one of Ultrathink's biggest advantages.
The Business Context Layer is where we encode how your business actually works: domain models (customers, policies, claims, assets, orders), relationships (who owns what, which processes depend on which systems), rules, SOPs, and business vocabulary.
Technically, this shows up as:
This is not a generic "data engineering" layer. It's business process engineering expressed as context and APIs. This is where our "Expert Guide + Pragmatic Engineer" archetype really shows up: we start from the P&L and workflows, then translate that into concrete models and retrieval patterns.
Demos love to ignore memory. Production systems can't.
We design memory architectures per use case, not as a generic "turn it on" feature:
Under the hood, durable execution engines like Temporal or DBOS handle the technical durability of long-running workflows. Memory in this layer is about what we surface to the user and the model so they have the right context without being overwhelmed.
Done well, memory is the difference between "neat demo" and "this feels like it understands how we work."
If the Business Context Layer is "what the world looks like," the Tools & Integration Layer is "what we can do about it."
Here, we design and expose capabilities for LLMs and agents:
We explicitly borrow from data mesh principles: each domain team owns its data and its tools, but publishes them through a clean, discoverable contract so other teams and agents can compose them.
Security-wise, this layer almost always requires an identity-aware proxy and carefully designed RBAC so that not every agent can hit every tool with every permission. We typically pair this with Axon-hosted MCP registries and catalogs deployed in the client's cloud, so data never leaves existing security boundaries.
AI applications are distributed systems with complex interdependencies.
A single refund workflow might touch: the UI, the model gateway, multiple tools (billing, CRM, ticketing), multiple databases, and external providers. Each call can fail in interesting ways. Network partitions, provider outages, partial writes, race conditions. This is where durable execution matters.
We lean on orchestration frameworks like Temporal or DBOS to:
We also favor event-sourced architectures where state changes are modeled as streams of events—making it easier to rebuild state, audit what happened, and drive real-time updates across the rest of the stack.
Without durable orchestration, you're asking a stateless web API to coordinate a web of systems and hoping nothing ever goes wrong.
This is central nervous system territory.
The model gateway is a shared layer that sits between your apps and all model providers. We typically use components like LiteLLM or emerging gateways and then extend them. Key responsibilities:
This is also where we future-proof: clients will not have "one model to rule them all." They'll have a portfolio—generalist LLMs, domain-specific models, open-source models, internal fine-tunes—and the gateway makes that complexity consumable.
Safety is not a single endpoint you call at the end. It's a layered system.
We distinguish between:
We use the gateway and orchestration layers to enforce:
Importantly, safety ties back to the Action Potential Index: some use cases should never be automated beyond decision support because the risk tolerance is effectively zero. We make that explicit up front, not after a compliance review blows up the project.
Prompts are not string literals sprinkled through the codebase. They are product surface area.
We treat prompts and related configuration as versioned, testable artifacts:
We typically manage this in a prompt management system (or internally in Axon) so product teams and domain experts can iterate without a full deployment cycle.
Prompt design also shapes how agents think: planner prompts vs worker prompts, decomposition strategies, when to ask for clarification vs when to act. It's part art, part engineering discipline.
You can't improve what you can't see.
We split this layer into:
We rely on both offline evaluation (score changes before rollout) and online monitoring (watch behavior drift in production). This is where we bridge our Model Efficacy Audit into day-to-day operations: the same metrics that justified the architecture also govern whether it's still performing.
This is where we move from "it works" to "it keeps getting better."
We explicitly separate different kinds of experimentation, because the tools and risks are different:
In Axon, this all plugs into The Synapse Cycle™: observation → hypothesis → experiment → rollout, tied back to the KPIs we defined during Discovery and Measurement.
Security and governance are not a lonely box at the bottom of the diagram. They're an operating model that spans every layer.
We typically recommend:
From an infrastructure perspective, this often looks like:
And a critical disclaimer: we don't replace your compliance teams. We design systems that make it easier for them to do their jobs with the frameworks and regulations you're already subject to.
For us, this isn't just a pretty model.
We use:
And we don't stop at launch. Our Outcome Partnership model ties our success to the business KPIs we agreed on together—we're structurally incentivized to keep the system improving, not to sell you another strategy deck.
This blog post is the executive summary. The full whitepaper goes deeper—with reference architectures, vendor landscape analysis, implementation patterns, and a layer-by-layer technical breakdown for leaders who need to understand the complexity without getting lost in it.
Take the next step from insight to action.
No sales pitches. No buzzwords. Just a straightforward discussion about your challenges.